以太坊数据结构详解

以太坊的实现中涉及了多种数据结构和编码规则,全面深入地理解这些内容对研究者和开发者来说至关重要。目前,该领域的主要信息来源是以太坊黄皮书、以太坊开发者文档以及网络上大量的非正式博客文章。黄皮书内容全面,但难称详略得当,易读性较低,且省略了智能合约数据的结构和存储信息。以太坊开发者文档的内容组织散乱,依赖众多外部博客和视频链接的补充完善。以太坊创始人 Antonopoulos 和 Wood 出版了 Mastering Ethereum 一书,但该书主要面向终端用户,并未深入讲解以太坊内部的技术细节。为弥补相关信息的空缺,本文将对以太坊数据结构进行汇总,目标是在保持简洁性的同时涵盖足够的细节,在一定的形式化视角基础上,通过实例和插图提升内容的可读性。
本文将首先介绍相关的基本数据结构,随后阐述其扩展形式 Merkle Patricia Trie 的结构和编码规则。之后是对区块的结构概述,以及对数据表示中 Trie 结构的详细介绍。
基础数据结构
Patricia Trie
高效搜索的标准方法之一是使用树 (Tree) 结构,树有多种形式,其中最为常见的是二叉搜索树。二叉搜索树可以构成前缀树 (Prefix Tree),在这种树中,具有相同前缀的键会共享从根节点到叶节点的路径。在前缀树中搜索键时,依次按顺序逐个检查字符,确认树中是否存在与当前字符匹配的子节点。如果存在,则向下遍历到该子节点,然后继续匹配下一个字符,重复这一过程。图 3 中左侧是用于二进制编码的前缀树示例。如图例所示,该树编码了四个二进制键,从根节点到叶节点形成了四条路径。
搜索树的缺点主要体现在其遍历效率上,在处理长公共前缀的键时,必须遍历多个子节点,特定情况下树会退化为链表,使查找时间复杂度从 $O(logn)$ 增加到 $O(n)$。
为了解决该问题,Fredkin 提出了 Trie Memory1。他将数据表示定义为表格形式,其中表的列代表节点,行代表分支。行数取决于分支数,例如,表示二进制数据需要两行(0 和 1),表示十六进制字符串则需要十六行(0 到 F)。列数则相当于将数据表示为树时的深度。该表的每格可包含对子节点的引用或字符串。引用子节点用目标列号表示。若存储字符串,则相当于键的后缀,终止当前路径。
Trie 这一名称源于其用途:信息检索 (Information Retrieval)
查找过程从逐字符遍历输入键开始。首先,在当前字符所在的行中查找。如果该行包含一个字符串,则路径终止,键已找到。如果该单元格包含指向另一个节点(即另一列)的链接,则该列包含所有编码键的所有可能分支。为了找到特定的键,从输入键中取出下一个字符,并找到与该字符匹配的行。这一行和当前列一起确定一个表格单元格。该单元格再次被分析,算法递归进行。如果单元格为空(即既不包含下一列的链接也不包含字符串),则表示输入键没有在表中编码。
图 1 是 Memory Trie 的示例,其中编码了四个十六进制的键。所有键的前四个字符相同,因此前四列引用了下一列。随后出现分支,即列 5 包含了对列 6、7、8 的引用。列 5 本身表示键的下一个字符所对应的行——行 0、2、F 对应编码键的第五个字符。列 6、7、8 包含了键的后缀,路径终止。
 图1 Memory Trie 示例
图1 Memory Trie 示例
Trie 在速度上很高效,因为可表示为二维数组,从而通过索引实现快速访问。但当存储的键值对分布稀疏时,Trie 会产生较大的内存开销,导致大量的空间浪费。
另外,原始 Trie 结构只能加速查找以相同前缀开头的键,或通过逆序存储来处理键的公共后缀,但无法解决键在中间部分有相同路径的情况。
Morrison 在论文2中提出的 Patricia Trie 解决了这一缺陷。Patricia Trie 对原始 Trie 结构进行了压缩优化,每个节点不仅存储路径信息,还记录了可以在匹配键时跳过的位数。在原始 Trie 中,键的公共前缀部分会通过多个节点表示,而在 Patricia Trie 中,这些公共路径会被压缩成一个单一节点。由此 Patricia Trie 减少了不必要的节点存储,在加速查找过程的同时,减少了内存开销。
图 3 右侧展示了 Patricia Trie 的例子,数据集中的所有键都以“11”开头,因此可以跳过两位,从键的第三位开始进行分支。值得注意的是,Patricia Trie 最初是为二叉树提出的,图 2 将图 1 中的示例表示为了 Patricia 格式,其中元组‘4(5)’表示在访问列 5 之前,已经跳过了四列。
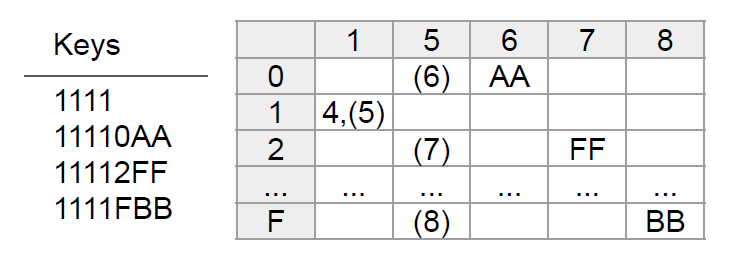 图2 Memory Patricia Trie 示例
图2 Memory Patricia Trie 示例
Merkle Tree
Ralph Merkle 提出的 Merkle Tree 3是一种用于快速验证数据集一致性的密码学数据结构。其核心特征是每个节点包含其子节点的哈希值,叶子节点则链接到编码数据集的实际值。该结构通常采用非对称哈希函数来保护原始数据。
Merkle Tree 的核心价值在于允许各方在不交换完整数据集的情况下验证数据一致性,这在分布式环境中尤为重要,因为直接比对大量复制数据往往不切实际。Merkle Tree 为数据集提供了唯一的哈希标识,有效防止了恶意或无意的数据修改。参与者可以通过比对哈希值来验证数据的完整性和一致性。由于每个子集都被哈希化,参与者可以仅交换子哈希,无需处理完整数据集。任何节点的篡改都会导致从该节点到根节点的哈希链不匹配,从而暴露错误。
在区块链这样的分布式无信任环境中,Merkle Tree 提供了理想的解决方案。它不仅提供了基于哈希的有效性证明,而且哈希值的小体积特性使其非常适合在互联网环境中传输,有效解决了区块链中数据验证和同步的关键挑战。图 3 中间是 Merkle Tree 的示例。节点自下而上均被哈希化,叶子节点仅对其自身进行哈希,而所有其余的父节点递归地对其子节点的哈希进行哈希。当需要在各方之间验证数据一致性时,可以验证任何节点的哈希值。
值得注意的是,Merkle Tree 在最初设计中仅包含哈希值,实际数据存储在外部。以太坊进一步创新,提出了将哈希和数据统一封装在树结构中的方法,这一部分将在本文后续章节详细阐述。
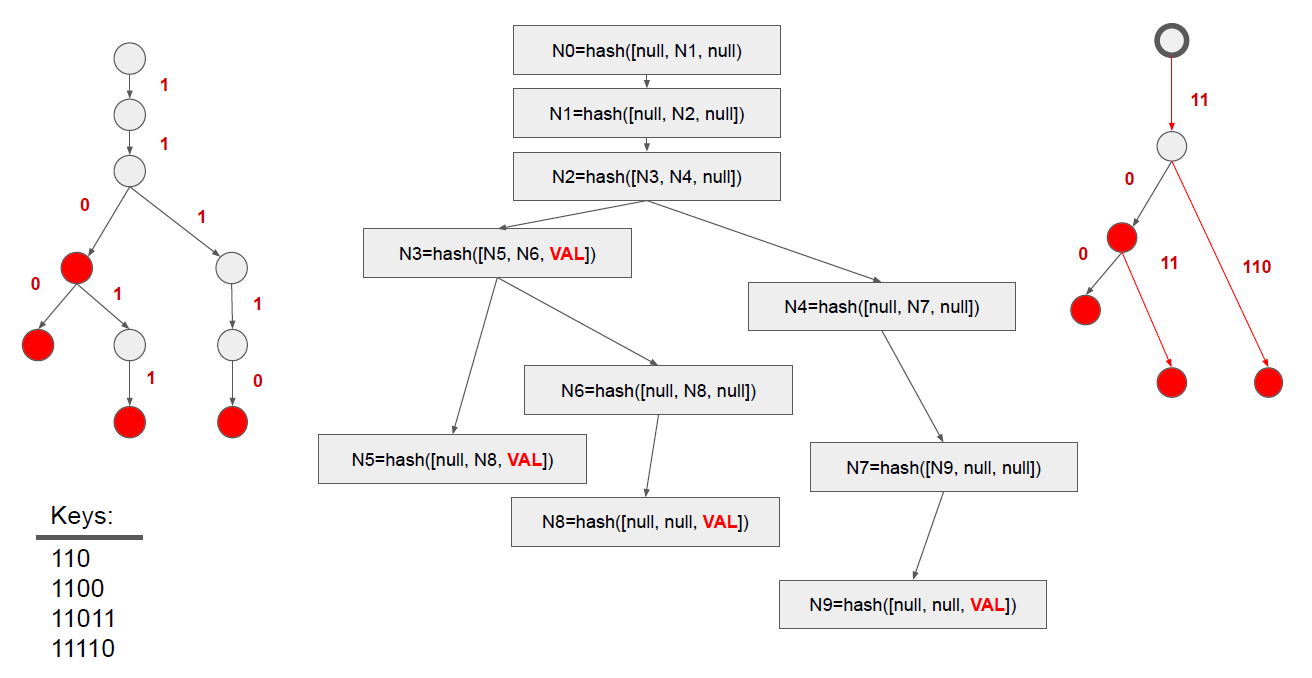 图3 Trie, Merkle Tree, Patricia Trie
图3 Trie, Merkle Tree, Patricia Trie
Merkle Patricia Trie
Merkle Patricia Trie (MPT) 是融合并扩展了 Patricia Trie 的高效存储和 Merkle Tree 的防篡改验证特性的数据结构4。该结构巧妙地将主键的公共路径组合在单一节点中,同时以 Merkle 证明的方式对每个节点进行哈希处理,实现了数据的高效组织和安全验证。
以太坊开发者在设计 Merkle Patricia Trie 时,考虑到了数据持久化问题。虽然黄皮书中提到“对存储的数据没有明确假设”,但随后又指出“实现将维护节点数据库”。这种设计思路表明 MPT 不仅是数据结构,也是数据库架构。这种设计简化了非结构化数据库(如 Geth 使用的 LevelDB)中结构化数据的存储,但同时也带来了一些挑战。研究表明,以太坊面临存储膨胀问题5,且由于持续计算哈希值导致读写放大,性能也有所下降6。
MPT 的独特之处在于允许将键的公共部分和后缀组合在一个节点中,仅在必要时进行分支。这种设计借鉴了 Patricia Trie 的思想,但扩展为了 16 个分支,并采用十六进制字符串代替位进行存储。与传统 Patricia Trie 不同,键的公共部分直接存储在节点中,而非仅存储跳过的位数。为实现 Merkle 证明,当 MPT 引用子节点时,引用的是子节点的哈希值。
这种创新结构不仅提高了数据存储和检索的效率,还增强了数据的安全性和完整性,为区块链技术中的数据管理提供了强有力的支持。
Merkle Patricia Trie 定义了三种类型的节点,结构如下:
- 分支节点 (Branch):包含 17 项 $[𝑖_0, 𝑖_1, …, 𝑖_{15}, 𝑣𝑎𝑙𝑢𝑒]$,用于处理键分叉,前 16 项对应十六进制字符 0-F,允许最多 16 个可能的分支。此设计类似于 Memory Trie 结构中通过表格列构建分支的方式。第 17 项用于存储值,仅在该节点是某个键的终止节点时使用。
- 扩展节点 (Extension):包含 2 项 $[𝑝𝑎𝑡ℎ, 𝑣𝑎𝑙𝑢𝑒]$,实现了路径压缩功能。当多个键共享公共前缀时,这部分前缀被存储在扩展节点中,避免了沿唯一路径的重复遍历。这一特性类似于 Patricia Trie 中跳过特定位数的机制。
- 叶节点 (Leaf):包含 2 项 $[𝑝𝑎𝑡ℎ, 𝑣𝑎𝑙𝑢𝑒]$,标志着树中路径的终点。同样采用压缩方法,将键的公共后缀在 $𝑝𝑎𝑡ℎ$ 中存储,借鉴了 Memory Trie 的特性。
图 4 是 Merkle Patricia Trie 的示例,其中键以十六进制数表示。所有键共享前缀“1111”,因此根节点被创建为扩展节点以分组此前缀。随后的分支节点在字符‘0’、‘2’和‘F’处处理键的分叉。键“1111”在此终止,其值存储在分支节点中。其余键形成叶节点,存储各自的后缀和对应值。
值得注意的是,实际实现中,父节点到子节点的每个链接都是通过子节点的哈希 $hash(node)$ 表示来引用的。但 MPT 结构中的节点是多元素(结构化)记录,而哈希函数是对二进制字符串计算的。因此必须将结构化的节点编码为字节数组,以便计算哈希值。这一过程将在后续章节详细阐述。
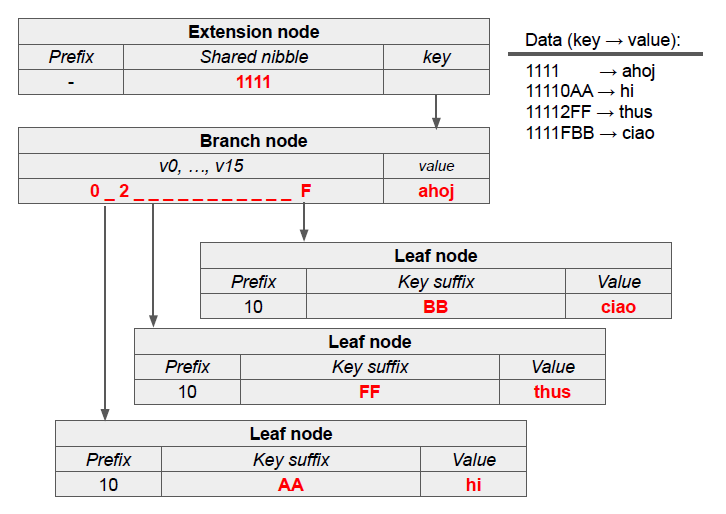 图4 Merkle Patricia Trie 示例
图4 Merkle Patricia Trie 示例
数据结构编码
Trie 结构的编码是将结构化节点转换为适合哈希计算和持久化存储的字节数组的过程。这一过程主要包括两个步骤:十六进制前缀编码(Hex Prefix Encoding, HP)和递归长度前缀编码(Recursive Length Prefix, RLP)。
十六进制前缀编码 HP
在 Merkle-Patricia Trie 中,存储的数据被编码为字节序列。叶节点和扩展节点使用 HP 编码函数进行处理。HP 编码在以太坊黄皮书中有形式化定义,其核心目的是将任意数量的半字节 (nibble) 编码为二进制流,使两个 4 位的半字节组成一个 8 位的字节,即半字节被编码为序列:$\lbrace 16𝑥_𝑖 + 𝑥_{𝑖+1} \lvert 𝑖 ∈ [0,\ldots,\lVert𝑥\rVert−1) \rbrace$
HP编码的特点包括:
- 添加前缀半字节:这个半字节的倒数第二位用于区分叶节点(1)和扩展节点(0);最低位则表示编码数据长度的奇偶性(偶数为0,奇数为1)。
- 长度调整:为确保解码时能准确重建原始值,存储的半字节数量必须为偶数。因为标准计算机无法仅存储半个字节。如果原始半字节数为奇数,在前缀半字节后插入一个值为‘0’的半字节作为填充。若为偶数,则直接在前缀半字节后继续编码路径。
如下表所示:
| Hex | Bits | Node Type | Path Length |
|---|---|---|---|
| 0 | 0000 | Extension | Even |
| 1 | 0001 | Extension | Odd |
| 2 | 0010 | Leaf | Even |
| 3 | 0011 | Leaf | Odd |
如下例所示,括号表示包含两个半字节的字节,为偶数长度数据添加了一个填充零作为第二个半字节,而奇数长度数据则紧跟在第一个半字节之后:
| Prefix | Payload | Node Type | Path Length |
|---|---|---|---|
| $[0,0]$ | $[x_1,x_2][x_3,x_4]$ | Extension | Even |
| $[0,x_1]$ | $[x_2,x_3][x_4,x_5]$ | Extension | Odd |
| $[2,0]$ | $[x_1,x_2][x_3,x_4]$ | Leaf | Even |
| $[3,x_1]$ | $[x_2,x_3][x_4,x_5]$ | Leaf | Odd |
以下两例分别展示了用 HP 编码的偶数和奇数长度字符串。例 1 编码了奇数个字符,因此前缀为‘1’或‘3’,后面紧跟有效负载,两个字符存储在一个字节中。例 2 包含偶数个字符,因此前缀为‘0’或‘2’,后跟附加的填充‘0’,然后是有效负载。
-
$[5, 6, 7, 8, 9] → [15, 67, 89] ∨ [35, 67, 89]$
-
$[4, 5, 6, 7, 8, 9] → [00, 45, 67, 89] ∨ [20, 45, 67, 89]$
递归长度前缀编码 RLP
在Merkle Patricia Trie中,节点结构经过 HP 编码后被压缩为字节数组,但仍保留多数组结构。为了实现高效的持久化存储和哈希计算,需要将这些多维数组结构进一步扁平化为单一字节数组。
以太坊黄皮书中定义了递归长度前缀函数来解决这个问题。RLP 函数的核心功能是将输入的一组数组序列化为一个扁平的字节数组,本质是将所有子数组转换为一个长数组,在每个原始子数组的序列前添加其长度信息和一个位掩码,用于标识该子数组原本是数组还是字符串。展平结构的每一级开始处会添加所有子数组的总长度信息。
RLP 根据数据类型和长度,采用不同的编码策略,以实现最优的空间利用,主要规则如下:
-
单字节值(≤ 127),直接存储,无需修改。对字节的 $b$:
\[RLP: b \rightarrow b\] -
短字符串(≤ 55字节),对字符串 $s$:
\[RLP: s \rightarrow [\text{0x80} + \lVert s \rVert, s]\]其中,$\lVert𝑠\rVert$ 表示字符串 $𝑠$ 的长度,字符串本身紧跟在此前缀之后。可以看到,RLP 对短字符串的编码非常高效,只需要一个额外的字节来存储前缀和字符串长度。
-
短数组(总长度 ≤ 55字节),对一组数组 $S$:
\[RLP: S \rightarrow [\text{0xc0} + \lVert ex(S) \rVert, ex(S)]\]其中,函数 $𝑒𝑥$ 对集合 $𝑆$ 中的每个数组进行 RLP 编码:
\[ex: S \rightarrow (RLP(s_i) | s_i \in S)\]这种数组的编码也非常高效,仅需要一个字节来存储前缀和总长度。
-
长字符串(< 2^64 字节),对字符串 $s$:
\[RLP: s \rightarrow [\text{0xb7} + numB(\lVert s \rVert), \lVert s \rVert, s]\]函数 $\text{𝑛𝑢𝑚𝐵}:𝑁 \rightarrow 𝑁$ 计算存储输入值所需的字节数。例如,长度小于 0xFF 的字符串需要一个字节来表示其长度,长度在 0xFF 到 0xFFFF 之间的需要两个字节等。这种情况下 RLP 在表示字符串长度时需要更多字节,但如果字符串不是特别长,该函数仍然较为高效。例如,长度为 0xFFFF 的字符串仅需三个额外字节来编码(1 个用于前缀,2 个用于长度)。
-
长数组(< 2^64 字节),对一组数组 $S$:
\[RLP: S \rightarrow [\text{0xf7} + numB(\lVert ex(S) \rVert), \lVert ex(S) \rVert, ex(S)]\]对于长嵌套数组,RLP 函数首先添加前缀,接着是表示长度所需的字节数,之后是长度本身,最后是递归 RLP 编码的有效负载。
-
超长负载(≥ 2^64 字节):不支持编码。
下面通过四个示例来说明RLP函数的应用:
-
对简单字符串“ABCD”进行编码,使用前缀 0x80 加上字符串的长度 4:
\[ABCD \rightarrow [\text{0x80} + 4, A, B, C, D]\] -
对包含“AB”和“CDE”的两个数组进行编码,使用前缀 0xc0 加上剩余编码负载的长度:
\[[AB] [CDE] \rightarrow [\text{0xc0} + 7, \text{0x80} + 2, A, B, \text{0x80} + 3, C, D, E]\] -
对长字符串进行编码。假设有长度为 300 个字符的字符串,缩写为“A ··· B”。为了表示长度,需要用十六进制形式的 0x12C ≡ 300。该数值需要两个字节,使用长字符串的前缀 0xb7 并加上 2,随后存储表示长度的两个字节,最后是字符串本身:
\[A ··· B \rightarrow [\text{0xb7} + 2, \text{0x1}, \text{0x2C}, A, \cdots , B]\] -
递归地存储两个数组 [A ··· B] [ABCD],其中一个包含长字符串,另一个包含短字符串。首先自底向上编码,应用前面示例中长字符串和短字符串的两条规则,创建两个字节序列 [0xb7 + 2, 0x1, 0x2C, A, ··· , B] 和 [0x80 + 4, A, B, C, D]。接下来先使用长数组的前缀:0xf7,并计算新的有效负载的长度,0x134 ≡ 308,该数字仍需两个字节存储。因此最终的编码包括前缀 0xf7 加上 2,字节 0x1, 0x34 以及两个已编码的数组,即:
RLP 编码的优势在于其高效性和灵活性。与 JSON 等文本标记语言相比,RLP 仅需少量前缀字节就能表示复杂的数据结构,大大降低了存储和传输开销。此编码方法是 Merkle Patricia Trie 中实现 Merkle 证明的基础。通过将节点转换为统一的字节数组格式,RLP 为后续的哈希计算提供了标准化的输入,从而支持了区块链中的数据完整性验证机制。
 图5 以太坊编码 Merkle Patricia Trie 示例
图5 以太坊编码 Merkle Patricia Trie 示例
图 5 中的示例是对图 4 的补充,展示了在以太坊中使用的节点编码。图中,扩展节点和叶子节点中的路径首先进行 HP 编码,随后各个节点通过 RLP 编码转换为字节数组。由此即可对整个节点进行哈希处理。父节点通过哈希值引用其子节点,从而为每个节点添加了 Merkle 证明。
键值存储持久化
Trie 节点经 HP 和 RLP 编码后转化为字节数组,适合存储于键值数据库。为解决哈希值无法揭示原始数据的问题,以太坊同时存储了节点的哈希值和 RLP 编码值,其中哈希函数采用 Keccak 函数。
每个节点在数据库中存储为一个$𝑘𝑒𝑦 → 𝑣𝑎𝑙𝑢𝑒$对,存储格式为:
\[keccak(RLP(node)) → RLP(node)\]其中 $𝑘𝑒𝑦 ≡ 𝑘𝑒𝑐𝑐𝑎𝑘(𝑅𝐿𝑃(𝑛𝑜𝑑𝑒))$ ,$𝑣𝑎𝑙𝑢𝑒 ≡ 𝑅𝐿𝑃(𝑛𝑜𝑑𝑒)$。每个节点的内容根据节点类型而有所不同:
- 扩展节点 $≡ [𝐻𝑃(𝑝𝑟𝑒𝑓𝑖𝑥 + 𝑝𝑎𝑡ℎ), 𝑘𝑒𝑦]$
- 分支节点 $≡ [𝑏𝑟𝑎𝑛𝑐ℎ𝑒𝑠, 𝑣𝑎𝑙𝑢𝑒]$
- 叶节点 $≡ [𝐻𝑃(𝑝𝑟𝑒𝑓𝑖𝑥 + 𝑝𝑎𝑡ℎ), 𝑣𝑎𝑙𝑢𝑒]$
其中,扩展节点中的 $𝑘𝑒𝑦$ 是子节点的哈希键。在分支节点中, $braches= (𝑘𝑒𝑦_𝑖 \vert 0 ≤ 𝑖 ≤ 15)$,如果分支存在,$𝑘𝑒𝑦_𝑖$ 为子节点的哈希键,否则为空。对于这两种节点类型,键通过已提到的公式计算:$𝑘𝑒𝑦 = 𝑘𝑒𝑐𝑐𝑎𝑘(𝑅𝐿𝑃(𝑛𝑜𝑑𝑒_𝑐))$,$𝑛𝑜𝑑𝑒_𝑐$ 为子节点。
需要注意的是,键的哈希表示是基于其 RLP 表示,从整个节点计算出来的。因为节点包含了子节点的哈希(除非是叶子节点),由此就构建起了数据结构的 Merkle 部分,即当前节点的哈希基于子节点的哈希计算而来。
另外,以太坊还使用了节点内联优化。如果子节点的 RLP 编码小于 32 字节,则不计算其哈希,而是将此节点直接存储在父节点内。此技术可以进一步压缩短节点的数据结构。
简单序列化编码 SSZ
SSZ (Simple Serialize) 是为以太坊 2.0 专门设计的序列化方法。其开发始于 2018 年,是以太坊研究团队为解决以太坊 1.0 中使用的 RLP 编码存在的一些限制而提出的。
SSZ 使用固定偏移量,使得在解码消息的个别部分时无需解码整个结构,这对共识客户端非常有用,令其可以高效地从编码消息中获取特定信息。SSZ 还专门设计为能够与 Merkle 协议集成,从而在 Merkle 化过程中带来相关的效率提升。由于共识层中的所有哈希值都是 Merkle 根,这种设计带来了显著的改进。此外,SSZ 还保证了数值的唯一表示形式。
目前,以太坊执行层客户端数据的序列化仍使用 RLP 编码,而共识层客户端以及 P2P 网络通信数据的序列化则使用 SSZ 编码,在以太坊 consensus-specs 仓库中维护相关规范。
为了使 SSZ 在共识和通信中都能发挥作用,给定类型 $T$ 的对象 $O1$ 和 $O2$,SSZ 应满足:
- 对合性:$deserialise⟨T⟩(serialise⟨T⟩(O1)) = O1$(通信所需)
- 单射性:$serialise⟨T⟩(O1) = serialise⟨T⟩(O2)$ 则 $O1 = O2$(共识所需)
属性 1 表示:当序列化某一类型的对象,然后再对结果反序列化时,得到的对象与开始时的对象完全相同。此属性是通信协议所必需的。
属性 2 表示:如果序列化同一类型的两个对象并得到相同的结果,那么这两个对象是相同的。换言之,两个不同的同类型对象,其序列化结果一定不同。此属性是共识协议所必需的。
除了这些基本功能要求外,SSZ 的目标相对简单:生成紧凑的序列化结果,并与 Merkle 化兼容,以及能够在不反序列化整个对象的情况下快速访问序列化中的特定数据位。
与 RLP 不同,SSZ 不是自描述的。RLP 数据可被解码成一个结构化对象,而无需预先了解该对象的具体形态,而 SSZ 则必须事先明确知道正在反序列化的对象类型。
SSZ 中定义了以下基本类型:
-
基本类型:
- 无符号整数:
uint8,uint16,uint32,uint64,uint128,uint256 -
字节:
byte,8 位不透明数据容器,在序列化和哈希时等同于uint8 - 布尔值:
boolean,取值为True或False
- 无符号整数:
-
复合类型:
-
向量:
Vector[T, N],有序的、固定长度的同质集合,其中 T 是任意 SSZ 类型,N 是元素个数,例如Vector[uint64, N] -
列表:
List[T, N],有序的、可变长度的同质集合,其中 T 是任意 SSZ 类型,N 是最大长度,例如List[uint64, N] -
容器:
Container[f1: T1, f2: T2, ..., fn: Tn],有序的异质集合(包含多种类型的值),其中 Ti 是任意 SSZ 类型,fi 是字段名例如:
1 2 3
class ContainerExample(Container): foo: uint64 bar: boolean
-
联合:
Union[T1, T2, ..., Tn],包含给定子类型之一的联合类型,其中 Ti 是任意 SSZ 类型,例如Union[None, uint64, uint32] -
位向量:
Bitvector[N],有序的、固定长度的布尔值集合,其中 N 是包含位数 -
位列表:
Bitlist[N],有序的、可变长度的布尔值集合,其中 N 是最大长度
-
SSZ 序列化的目标是将任意复杂的对象表示为字节字符串。基本类型序列化非常简单,元素只需转换为十六进制字节即可。
而对于复合类型,序列化过程则更为复杂,因为复合类型包含多个可能具有不同类型或不同大小的元素,当元素都具有固定长度时(即无论其实际值如何,元素的大小始终不变),序列化过程只是将复合类型中的每个元素按顺序转换为小端字节串,然后将其进行拼接。序列化后的对象以与反序列化对象中出现的顺序相同的方式表示固定长度元素的字节列表。
对于具有可变长度的类型,实际数据会在序列化对象中被其位置的“偏移量 (offset) ”所替代。实际数据会被添加到序列化对象末尾的堆中。偏移量值是实际数据在堆中的起始索引,起到指向相关字节的指针作用。可参考图 6。
 图6 SSZ 序列化编码图解 | 图源:protolambda
图6 SSZ 序列化编码图解 | 图源:protolambda
以下通过实例详细说明 SSZ 序列化,数据来自以太坊信标链上 Slot 3080831 Attestation 87 对应的 IndexedAttestation :
IndexedAttestation 容器如下:
1
2
3
4
class IndexedAttestation(Container):
attesting_indices: List[ValidatorIndex, MAX_VALIDATORS_PER_COMMITTEE]
data: AttestationData
signature: BLSSignature
里面包含 AttestationData 容器:
1
2
3
4
5
6
class AttestationData(Container):
slot: Slot
index: CommitteeIndex
beacon_block_root: Root
source: Checkpoint
target: Checkpoint
其中又包含两个 Checkpoint 容器:
1
2
3
class Checkpoint(Container):
epoch: Epoch
root: Root
使用相关信息构建 IndexedAttestation 对象,并计算其 SSZ 序列化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
attestation = IndexedAttestation(
attesting_indices = [33652, 59750, 92360],
data = AttestationData(
slot = 3080829,
index = 9,
beacon_block_root = '0x4f4250c05956f5c2b87129cf7372f14dd576fc152543bf7042e963196b843fe6',
source = Checkpoint (
epoch = 96274,
root = '0xd24639f2e661bc1adcbe7157280776cf76670fff0fee0691f146ab827f4f1ade'
),
target = Checkpoint(
epoch = 96275,
root = '0x9bcd31881817ddeab686f878c8619d664e8bfa4f8948707cba5bc25c8d74915d'
)
),
signature = '0xaaf504503ff15ae86723c906b4b6bac91ad728e4431aea3be2e8e3acc888d8af'
+ '5dffbbcf53b234ea8e3fde67fbb09120027335ec63cf23f0213cc439e8d1b856'
+ 'c2ddfc1a78ed3326fb9b4fe333af4ad3702159dbf9caeb1a4633b752991ac437'
)
print(attestation.encode_bytes().hex())
此对象序列化结果为:
1
2
3
4
5
6
7
e40000007d022f000000000009000000000000004f4250c05956f5c2b87129cf7372f14dd576fc15
2543bf7042e963196b843fe61278010000000000d24639f2e661bc1adcbe7157280776cf76670fff
0fee0691f146ab827f4f1ade13780100000000009bcd31881817ddeab686f878c8619d664e8bfa4f
8948707cba5bc25c8d74915daaf504503ff15ae86723c906b4b6bac91ad728e4431aea3be2e8e3ac
c888d8af5dffbbcf53b234ea8e3fde67fbb09120027335ec63cf23f0213cc439e8d1b856c2ddfc1a
78ed3326fb9b4fe333af4ad3702159dbf9caeb1a4633b752991ac437748300000000000066e90000
00000000c868010000000000
整理序列化结果如下:第一列是距字节串开头的字节偏移量。在每一行前标出了对应的数据结构部分,并将类型别名转换为其底层 SSZ 类型。注意整数类型是小端字节序,如 7d022f0000000000是十六进制数 0x2f027d ,十进制为 3080829。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
Part 1 (固定长度元素)
指向 attestation.attesting_indices 实际数据开头位置 0xe4 的 4 字节偏移量
00 e4000000
attestation.data.slot: Slot / uint64
04 7d022f0000000000
attestation.data.index: CommitteeIndex / uint64
0c 0900000000000000
attestation.data.beacon_block_root: Root / Bytes32 / Vector[uint8, 32]
14 4f4250c05956f5c2b87129cf7372f14dd576fc152543bf7042e963196b843fe6
attestation.data.source.epoch: Epoch / uint64
34 1278010000000000
attestation.data.source.root: Root / Bytes32 / Vector[uint8, 32]
3c d24639f2e661bc1adcbe7157280776cf76670fff0fee0691f146ab827f4f1ade
attestation.data.target.epoch: Epoch / uint64
5c 1378010000000000
attestation.data.target.root: Root / Bytes32 / Vector[uint8, 32]
64 9bcd31881817ddeab686f878c8619d664e8bfa4f8948707cba5bc25c8d74915d
attestation.signature: BLSSignature / Bytes96 / Vector[uint8, 96]
84 aaf504503ff15ae86723c906b4b6bac91ad728e4431aea3be2e8e3acc888d8af
a4 5dffbbcf53b234ea8e3fde67fbb09120027335ec63cf23f0213cc439e8d1b856
c4 c2ddfc1a78ed3326fb9b4fe333af4ad3702159dbf9caeb1a4633b752991ac437
Part 2 (可变长度元素)
attestation.attesting_indices: List[uint64, MAX_VALIDATORS_PER_COMMITTEE]
e4 748300000000000066e9000000000000c868010000000000
上例中,attesting_indices 列表是一个可变长度的集合,因此在 Part 1 中被表示为一个偏移量,该偏移量指向实际数据的位置,即从序列化数据的起始位置算起的第 0xe4 字节(第 228 字节)。列表的实际长度可以通过整个字节串的长度(252 字节)减去列表的起始位置(228 字节)再除以 8 字节来计算,由此就得到了三个验证者索引的列表。
所有剩余的项都是固定长度的,均被直接编码,包括递归编码的固定长度的 AttestationData 对象及其固定长度的 Checkpoint 子对象。
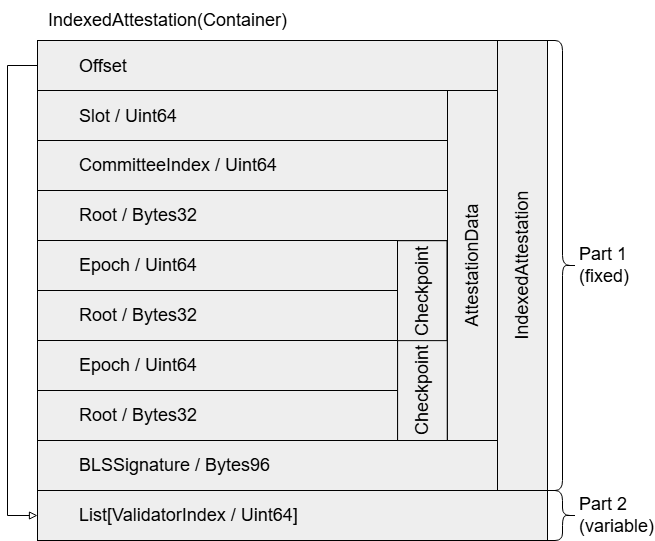 图7 IndexedAttestation 容器的序列化
图7 IndexedAttestation 容器的序列化
区块及交易
区块链本质上是一个分布式状态机。状态机是一个由一组状态和状态之间的转移规则所组成的系统,系统的状态随着输入的变化而改变。区块在这个系统中扮演着状态转换的角色。每个区块包含了一定时间段内所有已确认的交易数据以及前一区块的哈希值,由此形成了链式结构。每当一个新区块被添加到链上,区块链的全网状态便随着区块中所包含的交易得以更新。而交易是状态机输入的具体表现形式,是触发状态变更的基本单元,每笔交易描述了特定的状态转换操作,如资产转移或合约调用。交易的执行推动着全局状态的演进。
 图8 以太坊的状态转换 | 图源:以太坊开发者文档
图8 以太坊的状态转换 | 图源:以太坊开发者文档
区块链的整体思想是共通的,但各个区块链协议组织和存储数据的方式可能不同。以太坊使用的通用数据结构是 Merkle Patricia Trie。整个网络的当前状态(如账户余额、智能合约的存储数据)、交易数据等都被保存在相应的 Trie 结构中。每个区块的区块头中都包含指向各种 Merkle Patricia Trie 的链接。后续将详细介绍各种基于 Trie 的结构,这里主要对区块以及执行负载的结构进行简要介绍。
 图9 The Merge 前后的区块结构对比
图9 The Merge 前后的区块结构对比
如图 9 所示,以太坊完成 The Merge 后,共识机制由工作量证明 (PoW) 转变为权益证明 (PoS),区块结构也相应地发生了变化。以太坊 Bellatrix 升级中为信标链引入了新容器 ExecutionPayload 和 ExecutionPayloadHeader,PoW 区块中的大部分内容作为执行负载被添加进了 PoS 区块中,与共识层内容集成。
当前以太坊的区块结构如下:
1
2
3
4
5
6
class BeaconBlock(Container):
slot: Slot
proposer_index: ValidatorIndex
parent_root: Root
state_root: Root
body: BeaconBlockBody
| Field | Description |
|---|---|
slot |
区块所属的 Slot |
proposer_index |
选中提议该区块的验证者 ID |
parent_root |
前一个信标区块的哈希 |
state_root |
状态对象的根哈希 |
body |
信标区块体,包含多个字段 |
其中,信标区块体结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
class BeaconBlockBody(Container):
randao_reveal: BLSSignature
eth1_data: Eth1Data # Eth1 data vote
graffiti: Bytes32 # Arbitrary data
# Operations
proposer_slashings: List[ProposerSlashing, MAX_PROPOSER_SLASHINGS]
attester_slashings: List[AttesterSlashing, MAX_ATTESTER_SLASHINGS]
attestations: List[Attestation, MAX_ATTESTATIONS]
deposits: List[Deposit, MAX_DEPOSITS]
voluntary_exits: List[SignedVoluntaryExit, MAX_VOLUNTARY_EXITS]
sync_aggregate: SyncAggregate
# Execution
execution_payload: ExecutionPayload # [New in Bellatrix] [Modified in Deneb:EIP4844]
# Capella operations
bls_to_execution_changes: List[SignedBLSToExecutionChange, MAX_BLS_TO_EXECUTION_CHANGES] # [New in Capella]
blob_kzg_commitments: List[KZGCommitment, MAX_BLOB_COMMITMENTS_PER_BLOCK] # [New in Deneb:EIP4844]
| Field | Description |
|---|---|
randao_reveal |
由区块提议者提供的 BLS 签名,用于选出下一区块提议者 |
eth1_data |
有关存款合约的信息 |
graffiti |
任意数据字段,通常用于标记区块 |
proposer_slashings |
将被罚没的提议者列表,包含对提议者不当行为的证明 |
attester_slashings |
将被罚没的验证者列表,包含对验证者不当行为的证明 |
attestations |
验证者对当前区块的投票 |
deposits |
新的验证者存款信息 |
voluntary_exits |
验证者自愿退出的申请 |
sync_aggregate |
服务轻客户端的验证者子集 |
execution_payload |
包含执行层的完整信息 【Bellatrix 升级引入】【Deneb 升级扩展】 |
bls_to_execution_changes |
验证者更改提款凭证的请求 【Capella 升级引入】 |
blob_kzg_commitments |
对执行负载中 blob 数据的承诺 【Deneb 升级引入】 |
本文主要介绍以太坊的数据结构,主要关注执行层相关内容,因此不对共识层相关内容过多赘述。execution_payload 包含执行层的完整信息,其结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
class ExecutionPayload(Container):
# Execution block header fields
parent_hash: Hash32
fee_recipient: ExecutionAddress # 'beneficiary' in the yellow paper
state_root: Bytes32
receipts_root: Bytes32
logs_bloom: ByteVector[BYTES_PER_LOGS_BLOOM]
prev_randao: Bytes32 # 'difficulty' in the yellow paper
block_number: uint64 # 'number' in the yellow paper
gas_limit: uint64
gas_used: uint64
timestamp: uint64
extra_data: ByteList[MAX_EXTRA_DATA_BYTES]
base_fee_per_gas: uint256
# Extra payload fields
block_hash: Hash32 # Hash of execution block
transactions: List[Transaction, MAX_TRANSACTIONS_PER_PAYLOAD]
withdrawals: List[Withdrawal, MAX_WITHDRAWALS_PER_PAYLOAD] # [New in Capella]
blob_gas_used: uint64 # [New in Deneb:EIP4844]
excess_blob_gas: uint64 # [New in Deneb:EIP4844]
| Field | Description |
|---|---|
parent_hash |
前一区块的哈希值 |
fee_recipient |
接收交易费用的地址 |
state_root |
执行此区块后全局状态的根哈希 |
receipts_root |
交易收据树的哈希值 |
logs_bloom |
用于快速检索日志的布隆过滤器 |
prev_randao |
替代了mixHash字段,用于验证者随机选择的值 【EIP-4399 引入】 |
block_number |
当前区块的编号 |
gas_limit |
该区块的 gas 上限 |
gas_used |
该区块实际使用的 gas 量 |
timestamp |
区块创建的 Unix 时间戳 |
extra_data |
原始字节形式的任意附加数据 |
base_fee_per_gas |
每单位 gas 的基础费用 |
block_hash |
整个执行负载的哈希,不包括block_hash字段本身 |
transactions |
待执行交易列表 |
withdrawals |
提款对象列表 【EIP-4895 引入】 |
blob_gas_used |
该区块中的交易消耗的 blob gas 总量 【EIP-4844 引入】 |
excess_blob_gas |
当前区块链上 blob gas 使用量与预设目标的差值 【EIP-4844 引入】 |
巴黎升级中,根据 EIP-3675,原本 PoW 区块中的 ommersHash、difficulty、mixHash、nonce、ommers 等在 PoS 机制下无作用或无意义的字段被置为特定常量:
| Field | Constant value | Comment |
|---|---|---|
ommersHash |
0x1dcc4de8dec75d7aab85b567b6ccd41ad312451b948a7413f0a142fd40d49347 |
= Keccak256(RLP([])) |
difficulty |
0 |
|
mixHash |
0x0000000000000000000000000000000000000000000000000000000000000000 |
|
nonce |
0x0000000000000000 |
|
ommers |
[] |
RLP([]) = 0xc0 |
而 EIP-4399 中,将DIFFICULTY 操作码 (0x44) 更新并重命名为 PREVRANDAO,返回由信标链提供的随机信标的输出。PREVRANDAO 所暴露的值存储在 ExecutionPayload 中,原本用于存储 mixHash 值的位置,负载中的 mixHash 字段也被重命名为 prevRandao,如图 10 所示。
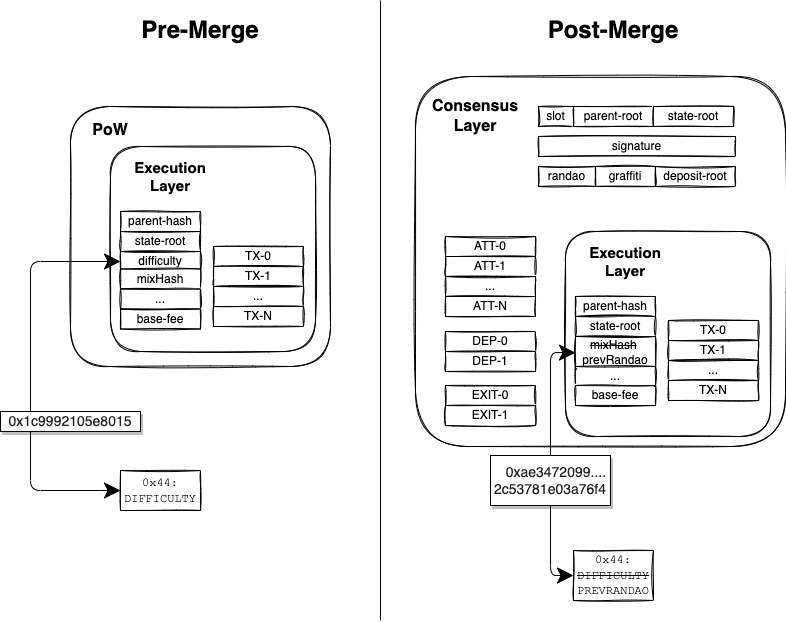 图10
图10 prevRandao字段的引入
随后的上海升级中,EIP-4895 为了实现质押提取功能,将共识层的验证者奖励和退出请求顺利传递到执行层,在 ExecutionPayload 中引入了 withdrawals 字段,在共识层和执行层之间建立无缝的数据传输。
坎昆升级中,被称为“Proto-Danksharding”的 EIP-4844 引入了“Blob-carrying Transaction”,以解决以太坊数据可用性问题,降低 Layer 2 Rollup 扩容方案的成本。为实现 Blob 存储费用的动态调整、平衡数据可用性和存储成本间的关系,EIP-4844 在 ExecutionPayload 中添加了 blob_gas_used 和 excess_blob_gas 两个字段。
以上是对以太坊 PoS 区块中执行负载 ExecutionPayload 的结构及变更过程的简要介绍,区块中相应的 ExecutionPayloadHeader 内容与之基本相同,仅将交易列表、提款列表替换为了交易根哈希 transactions_root 和提款根哈希 withdrawals_root。
state_root、receipts_root 和 transactions_root 字段分别指向相应的全局状态树 (World State Trie)、收据 (Receipts Trie) 和交易树 (Transactions Trie),后续章节将详细阐述,同时也会对logs_bloom 过滤器、gas_limit 和 gas_used 字段进行说明。
虽然共识层的
ExecutionPayloadHeader和执行层区块头在概念上是相互映射的,但在共识客户端和执行客户端的实现中二者的编码方式不同,为了维护向后兼容性,执行层保持了原有的 RLP 编码方式,共识层的内部操作则使用 SSZ 编码。EIP-6404 、EIP-6465、EIP-6466 已提议将交易树、提款树、收据树的 MPT 承诺转为 SSZ,以提升跨层一致性和轻客户端的验证效率,为此需要将容器的序列化算法由 RLP 格式更改为 SSZ 格式,进而会影响到执行层区块头中的相应字段。目前这几项 EIP 仍处于评议阶段。
数据表示
 图11 以太坊数据结构
图11 以太坊数据结构
如前所述,交易的执行是区块链中的基本过程。以太坊在此基础上进行了扩展,引入了智能合约这一关键特性。智能合约为一种特殊的程序,同样通过交易进行创建和执行,能够执行代码并将值存储至全局变量中,这就意味着以太坊需要存储的不仅仅是交易记录,还包括智能合约代码及相关的状态值。以太坊采用了 Merkle Patricia Trie 结构来实现这点,其具体细节将在后续部分阐述。
以太坊使用以下数据结构:收据树 (Receipts Trie)、交易树 (Transactions Trie)、全局状态树 (World State Trie) 和账户存储树 (Account Storage Trie)。
交易树
收据树和交易树用于记录每笔交易的执行结果。这两种树的特点是,一旦交易执行完毕,其内容就不可更改。这确保了所有已执行的交易被永久记录,无法撤销,从而保证了区块链的不可篡改性。
与之形成鲜明对比的是全局状态树,它随着区块链状态的变化而不断更新,实时反映最新的账户余额和智能合约状态。
在 MPT 中,每笔交易都被编码为一个键值对,以交易索引 $index$ 作为键,交易 $T$ 本身作为值,两者皆通过 RLP 编码处理。这种编码方式确保了数据的高效存储和快速检索,可以表示为:
\[𝑅𝐿𝑃 (𝑖𝑛𝑑𝑒𝑥) → 𝑅𝐿𝑃 (𝑇)\]以太坊执行层规范目前定义了以下几种主要的交易类型,以 Geth 客户端代码为例进行简要说明:
1
2
3
4
5
6
7
// Transaction types.
const (
LegacyTxType = 0x00
AccessListTxType = 0x01
DynamicFeeTxType = 0x02
BlobTxType = 0x03
)
-
传统交易 (Legacy Transaction):
1 2 3 4 5 6 7 8 9
type LegacyTx struct { Nonce uint64 // nonce of sender account GasPrice *big.Int // wei per gas Gas uint64 // gas limit To *common.Address `rlp:"nil"` // nil means contract creation Value *big.Int // wei amount Data []byte // contract invocation input data V, R, S *big.Int // signature values }
传统交易是最早的交易类型,在以太坊诞生之初就存在。其特点是使用固定的
gasPrice来计算交易费用。传统交易中不包含chainID,因此在跨链时可能存在重放攻击风险。 -
访问列表交易 (Access List Transaction)【EIP-2930 引入】:
1 2 3 4 5 6 7 8 9 10 11
type AccessListTx struct { ChainID *big.Int // destination chain ID Nonce uint64 // nonce of sender account GasPrice *big.Int // wei per gas Gas uint64 // gas limit To *common.Address `rlp:"nil"` // nil means contract creation Value *big.Int // wei amount Data []byte // contract invocation input data AccessList AccessList // EIP-2930 access list V, R, S *big.Int // signature values }
访问列表交易引入了
accessList字段,允许预先声明交易将访问的账户和存储槽,预热状态访问,减少EVM执行时的动态gas成本。此外还添加了chainID,提高了跨链安全性。但仍然使用传统的gasPrice机制进行交易的优先级排序和手续费支付。 -
动态费用交易 (Dynamic Fee Transaction)【EIP-1559 引入】:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
type DynamicFeeTx struct { ChainID *big.Int Nonce uint64 GasTipCap *big.Int // a.k.a. maxPriorityFeePerGas GasFeeCap *big.Int // a.k.a. maxFeePerGas Gas uint64 To *common.Address `rlp:"nil"` // nil means contract creation Value *big.Int Data []byte AccessList AccessList // Signature values V *big.Int `json:"v" gencodec:"required"` R *big.Int `json:"r" gencodec:"required"` S *big.Int `json:"s" gencodec:"required"` }
动态费用交易采用双层手续费模型:将
gasPrice拆分为基础手续费 (baseFee) 和小费 (tip)。其中基础手续费会随着网络需求自动调整,并会被销毁(使以太币成为了通缩资产),小费由用户设置,用于激励矿工优先处理交易。使用gasTipCap和gasFeeCap来控制交易费用。旨在优化网络的手续费模型,解决高峰期手续费波动过大的问题。动态费用交易继承了访问列表功能。 -
Blob 交易 (Blob Transaction)【EIP-4844 引入】:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
type BlobTx struct { ChainID *uint256.Int Nonce uint64 GasTipCap *uint256.Int // a.k.a. maxPriorityFeePerGas GasFeeCap *uint256.Int // a.k.a. maxFeePerGas Gas uint64 To common.Address Value *uint256.Int Data []byte AccessList AccessList BlobFeeCap *uint256.Int // a.k.a. maxFeePerBlobGas BlobHashes []common.Hash // A blob transaction can optionally contain blobs. This field must be set when BlobTx // is used to create a transaction for signing. Sidecar *BlobTxSidecar `rlp:"-"` // Signature values V *uint256.Int `json:"v" gencodec:"required"` R *uint256.Int `json:"r" gencodec:"required"` S *uint256.Int `json:"s" gencodec:"required"` }
Blob 交易是专为 Layer 2 扩展解决方案设计的交易类型,目的是为了降低 Rollup 解决方案的数据可用性成本,提升以太坊的可扩展性。引入了
blobFeeCap和blobHashes字段,用于处理暂时存储大量数据的 Blob (Binary Large Object)。Blob 交易继承了动态费用机制和访问列表功能。
每种交易类型都代表了以太坊协议的一次重要升级:传统交易为以太坊奠定了基础,EIP-2930 通过访问列表优化了复杂交易的 gas 使用,EIP-1559 彻底改革了以太坊的经济模型和费用机制,EIP-4844 则为以太坊未来的可扩展性提升铺平了道路。
本文的主要目标是为读者提供以太坊数据结构的概览。考虑到篇幅和重点,这里不会对各种复杂的交易类型进行详尽分析。为了使概念更加清晰易懂,接下来的讨论将以最基本的传统交易(下称交易)为例,深入阐述其结构和特点。
交易中包含多个字段:
| Field | Description |
|---|---|
| nonce | 交易的序号,用于跟踪交易顺序并防止重复交易 |
| gasPrice | 当前 gas 价格 (wei per gas) |
| gasLimit | 交易执行的最大 gas 限额 |
| to | 接收方地址,合约创建交易中为空 |
| value | 转移的资金量或新合约的初始余额 |
| data | 合约创建的代码或消息调用的输入数据 |
| v, r, s | 用于编码发送方签名的值 |
一笔交易可以执行以下三类操作:
- 账户间资金转移
- 智能合约创建
- 智能合约调用
不同操作使用的字段略有不同:
-
普通转账交易
to字段指定接收方地址,data字段为空,value字段指定要发送的 ETH 数量。 - 合约创建交易
to字段为空,data字段包含合约的字节码,value字段通常为 0(除非要在创建时向合约发送ETH)。 - 合约调用交易
to字段指定要调用的合约地址,data字段包含函数选择器和编码后的参数,value字段如果函数是 payable 的,可以指定发送的 ETH 数量,否则为 0。
1
2
3
4
5
6
7
8
9
10
// TransitionDb 执行状态转换
func (st *StateTransition) TransitionDb() (*ExecutionResult, error) {
// ... (代码略)
if contractCreation {
ret, _, st.gas, vmerr = st.evm.Create(sender, st.data, st.gas, st.value)
} else {
ret, st.gas, vmerr = st.evm.Call(sender, st.to(), st.data, st.gas, st.value)
}
// ... (代码略)
}
合约创建
智能合约通过一种特殊类型的交易部署到链上,图 12 以序列图的形式展示了这一过程。
 图12 合约创建及调用
图12 合约创建及调用
交易执行后,会在交易树 (Transaction Trie) 中创建一个包含所有相关字段的记录。对于合约创建而言,Trie 中的 data 字段会被填充为于生成新合约的 EVM 字节码。字节码通常由智能合约编译器预先生成,并随交易一起传输。由于是新合约部署,交易树中的to字段保持为空。
交易树中的 to 字段初始为空,因为合约部署的一部分任务就是创建新账户,to 字段的值尚未确定。智能合约部署后,系统立即在全局状态树中创建一个新的合约账户(图中显示为创建了一个新参与者)。这个新账户将合约的字节码存储在 codeHash 字段中。此外,系统还会创建一个新的存储空间,由一个存储树表示,该树的根节点保存在 storageRoot 字段中。如果合约创建时包含初始状态(即全局变量),也会存储在该树中。
从编程语言的角度来看,初始化代码是以构造函数的形式实现的。构造函数会与其方法体中的所有指令一同执行,因此构造函数可以通过程序变量来设置合约的初始状态。调用构造函数的结果就是合约本身,因为函数返回了新合约的主体,并通过 account 字段的 codeHash 与之关联,此过程可以类比为面向对象编程中创建对象实例。构造函数可以接受参数,参数以二进制形式附加到 data 字段中。
新创建的合约可以附带初始资金,资金存储在 balance 字段中。这一特性使得合约能够像人类用户一样持有资金,但同时也带来了潜在的安全风险,如臭名昭著的DAO攻击事件所示。在该事件中,攻击者利用合约中的漏洞,窃取了大量积累在单一账户中的以太币。
消息调用
一旦部署完成,合约可以被多次执行。合约执行一般是指其方法的执行,这一过程通过一个带有非空 data 字段的合约调用交易触发。这样以特定格式封装了方法签名和数据的合约执行被称为消息调用,此概念类似常见的 RPC(远程过程调用)或 RMI(远程方法调用)。再次参考图 12 中的 UML 图示,图中底部的人类参与者发起了三个带有消息调用的交易,交易从相应的账户中提取 codeHash,并执行智能合约的某个方法。合约调用交易必须在 to 字段中包含一个账户地址,以确定在查找 codeHash 时使用哪个具体合约账户。
调用合约的交易将方法签名和输入数据合并到 data 字段中。方法签名以哈希存储,后跟输入数据。输入数据采用抽象二进制接口(ABI)格式进行编码,这种格式允许将方法签名和输入数据作为一个二进制序列在单个字段中编码。
合约间的方法调用通过内部交易实现。这种机制与外部交易调用方法相同,但有两个主要区别:首先,内部交易不会记录在区块链上。其次,内部交易没有独立的 gasLimit,所消耗的 gas 费用由发起原始调用的交易承担,这一规则在嵌套调用合约时同样适用。这种设计使得创建合约库成为可能。这些库本身不收取费用,但当其被整合到其他合约中时,使用者需要考虑相关的成本。
v, r, s
交易的数字签名由三个值 (v, r, s) 构成。其中,r 和 s 是通过 ECDSA 签名算法计算得出的。以太坊特别采用了名为 secp256k1 的 ECDSA 实现。ECDSA 是基于椭圆曲线的对称函数,利用私钥和公钥对生成签名。第三个值 v 是恢复标识符,为一字节大小,用于从签名中获取公钥。将此公钥通过 Keccak 哈希算法处理后,其哈希值的前 20 个字节即等同于一个账户地址。因此,妥善保管私钥至关重要,因为私钥用于签署交易,并可证明用户作为账户所有者的身份。
收据树
每笔交易的执行结果都记录在交易收据树中。该树为每笔交易创建一个条目,至少包含一个指示交易执行是否正确的结果代码。此外,树中还可包含智能合约生成的日志消息,用于更详细地调试合约执行过程。通过分析收据树,交易发起者可以观察交易的执行时间,并可通过日志消息进行深入分析。
以太坊节点提供了一个便捷的 API,允许用户注册事件并在收到交易收据时收到通知。因此,用户通常先提交交易,然后通过这个 API 等待收据,因为交易的确切执行时间是无法预知的。
收据 Trie 的结构如下:键为交易索引 $𝑖𝑛𝑑𝑒𝑥$,值为收据 $𝑅$,组成键值对:
\[RLP(𝑖𝑛𝑑𝑒𝑥) → RLP(𝑅)\]收据在 Geth 客户端中的定义如下:
1
2
3
4
5
6
7
8
9
10
11
type Receipt struct {
Type uint8
PostState []byte
Status uint64
CumulativeGasUsed uint64
Bloom Bloom
Logs []*Log
// ...其他字段省略
}
type Receipts []*Receipt
-
Status:指示交易是成功还是失败(如 gas 不足而失败) CumulativeGasUsed:执行当前交易后相应区块中累计使用的 gas 总量,即所有前序交易和当前交易消耗的 gas 总和Logs:此交易产生的日志集合Bloom:包含日志条目哈希的 Bloom 过滤器,用于加速日志搜索
布隆过滤器 (Bloom Filter)
布隆过滤器是一种空间高效的概率性数据结构,用于提升以太坊中与智能合约交互相关的日志检索效率。布隆过滤器通过概率方法快速判断某个特定元素(如交易或事件)是否属于某集合,从而优化区块链上日志查询的过程。具体而言,布隆过滤器由一个大小为 \(m\) 的位数组和 \(k\) 个独立的哈希函数组成。每个哈希函数将一个元素映射到数组中的一个位上。当将一个元素添加到布隆过滤器时,该元素会通过 \(k\) 个哈希函数处理,哈希函数会将对应的位设置为1。要检查某个元素是否在集合中,将该元素使用相同的 \(k\) 个哈希函数进行哈希处理。如果哈希位置中有任意一位是0,则该元素肯定不在集合中;如果所有位都为1,则元素可能在集合中,但需要进一步验证(存在哈希碰撞的可能性)。也就是说,布隆过滤器不会漏报,但可能误报(假阳性)。
布隆过滤器占用的空间远小于直接存储所有日志条目,可存储于主存、缓存中,或在分布式系统中靠近客户端存储,该特性令其特别适合在区块链环境中使用。在耗费大量资源查询存储之前,客户端可先查询过滤器,布隆过滤器能够快速确认主键的不存在性,从而有效减少无效查询。
日志消息 (Message Log)
关于日志消息:收据树可包含智能合约生成的日志消息。在 Solidity 合约中,日志消息通过 emit 关键字发出,而在字节码层面,则由 EVM 指令 LOG0 至 LOG4 表示。
日志在 Geth 客户端中的定义如下:
1
2
3
4
5
6
7
8
9
type Log struct {
// address of the contract that generated the event
Address common.Address `json:"address" gencodec:"required"`
// list of topics provided by the contract.
Topics []common.Hash `json:"topics" gencodec:"required"`
// supplied by the contract, usually ABI-encoded
Data []byte `json:"data" gencodec:"required"
// ...其他字段省略
}
Address:触发日志的地址,即执行该智能合约的账户Topics:用于标识事件类型的主题Data:包含日志消息本体的字节序列
日志消息可包含任意数据,且每条消息可分配一个主题。客户端可以选择只监听特定主题的消息,无需处理所有消息。
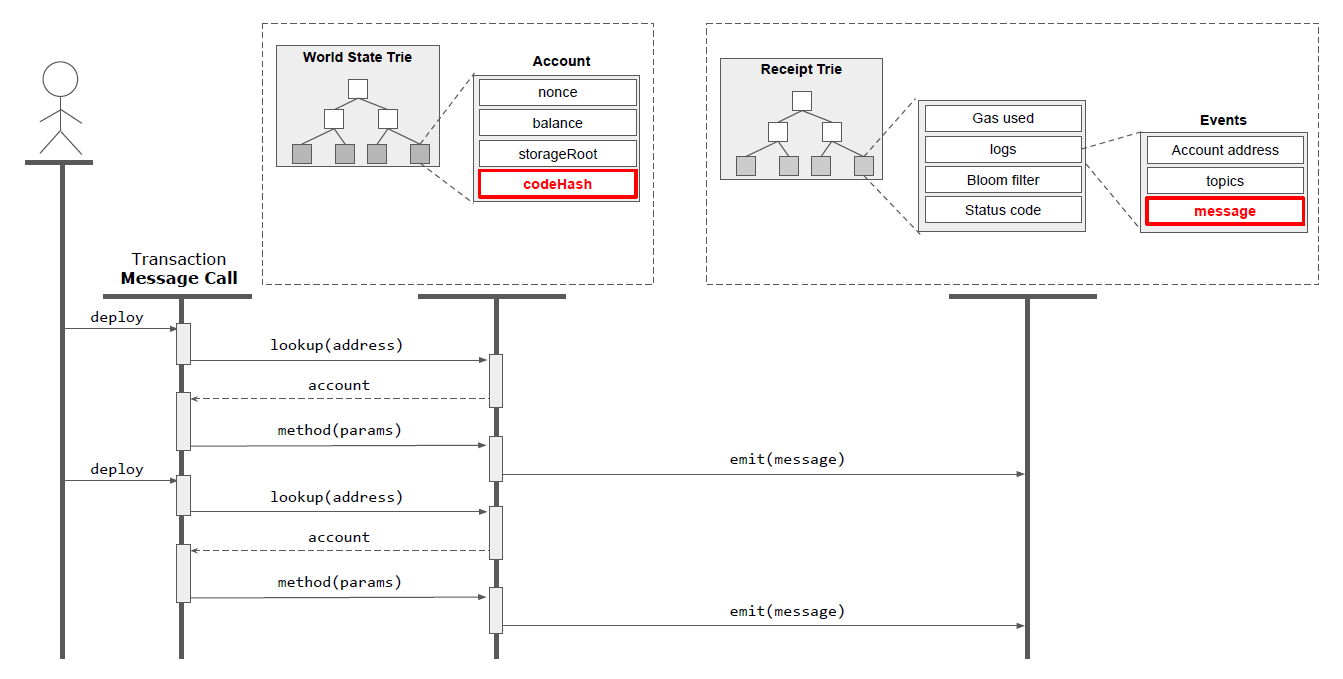 图13 日志事件更新收据树
图13 日志事件更新收据树
日志条目的创建过程可通过图 13 的 UML 序列图来理解。用户首先需提交执行智能合约的交易,即通过消息调用执行合约方法。该交易的 to 字段必须包含目标账户,该账户在全局状态树中代表智能合约。合约执行后,如果方法中包含 emit 关键字,相应消息将进入日志条目。
全局状态树
不同于静态的交易树和收据树,全局状态树是动态可变更的数据结构,用于记录区块链的最新状态。全局状态树维护了地址与账户之间的映射,树中的路径会链接到账户信息记录。账户地址是一个 160 位的标识符,由用户签名公钥的前 20 个字节生成。
以太坊中包含两类账户:外部拥有账户 (Externally Owned Account,EOA) 和合约账户 (Contract Account)。两者在全局状态树中都是叶子节点,结构相同,但可通过某些字段的值来区分。
Geth 客户端的实现中 Trie 结构如下:
1
2
3
4
5
6
type Trie struct {
root node
owner common.Hash
db *Database
// ... (其他字段)
}
root:树的根节点owner:trie 的所有者(通常是状态根哈希)db:底层数据库,用于持久化存储
具体到状态树,实现中管理整个以太坊状态的核心结构是 StateDB:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
type StateDB struct {
db Database
prefetcher *triePrefetcher
trie Trie
hasher crypto.KeccakState
accounts map[common.Address][]byte
accountsOrigin map[common.Address][]byte
storages map[common.Address]map[common.Hash][]byte
storagesOrigin map[common.Address]map[common.Hash][]byte
stateObjects map[common.Address]*stateObject
stateObjectsPending map[common.Address]struct{}
stateObjectsDirty map[common.Address]struct{}
journal *journal
validRevisions []revision
nextRevisionId int
// ... (其他字段)
}
这个结构包含了几个关键组件:
trie:即全局状态树accounts和storages:账户和存储数据的缓存stateObjects:当前活跃的账户状态对象journal:状态修改日志,用于支持回滚操作
每个账户 $A$ 通过其地址 $address$ 进行映射,地址进一步通过哈希生成键值对:
\[keccak(address) \rightarrow RLP(A)\]实现中账户状态由 StateAccount 结构表示:
1
2
3
4
5
6
type StateAccount struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
CodeHash []byte
}
Nonce:对 EOA 表示发送交易次数;对合约账户表示创建次数。Balance:账户可用资金。StorageRoot:账户存储树的 Merkle 根。EOA 此字段为空。CodeHash:账户合约代码的哈希,具体的 EVM 字节码存储在底层数据库中,以该哈希为键。EOA此字段为空。
EOA 通常由用户持有,存储用户资金,类似标准银行账户。合约账户包含智能合约,通过 CodeHash 链接合约字节码,并通过 StorageRoot 引用账户存储树,用于持久化合约数据。
全局状态树通过状态转换进行操作,交易类型必须与账户类型匹配。
全局状态树是不断变化的结构。对于涉及 EOA 的交易,账户余额根据交易规定更新。对于涉及智能合约账户的交易,存储在 CodeHash 中的合约根据 Data 字段执行。合约执行通常涉及状态变化,即更新合约全局变量,这会触发 StorageRoot 更新,进而修改状态树。
实现中,stateObject 结构代表了一个账户的完整状态:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
type stateObject struct {
address common.Address
addrHash common.Hash
data types.StateAccount
db *StateDB
trie Trie
code Code
originStorage Storage
pendingStorage Storage
dirtyStorage Storage
// ... (其他字段)
}
这个结构维护了账户的各种状态,包括存储树、合约代码和存储缓存。
当需要访问或修改账户状态时,StateDB 首先尝试从 stateObjects 缓存中获取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func (s *StateDB) getStateObject(addr common.Address) *stateObject {
// 首先检查缓存
if obj := s.stateObjects[addr]; obj != nil {
return obj
}
// 从底层trie加载
enc, err := s.trie.TryGet(addr.Bytes())
if err != nil {
s.setError(err)
return nil
}
if len(enc) == 0 {
return nil
}
var data types.StateAccount
if err := rlp.DecodeBytes(enc, &data); err != nil {
// ... 错误处理
}
// 创建新的stateObject并缓存
obj := newObject(s, addr, data)
s.setStateObject(obj)
return obj
}
对账户状态的修改会更新 stateObject 并标记为脏:
1
2
3
4
func (s *StateDB) setStateObject(object *stateObject) {
s.stateObjects[object.Address()] = object
s.stateObjectsDirty[object.Address()] = struct{}{}
}
存储变更会更新 pendingStorage 和 dirtyStorage:
1
2
3
4
5
func (s *stateObject) SetState(db Database, key, value common.Hash) {
// ... (变更记录和状态更新)
s.pendingStorage[key] = value
s.dirtyStorage[key] = value
}
当需要将状态变更持久化时,Commit 函数被调用:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
func (s *StateDB) Commit(deleteEmptyObjects bool) (common.Hash, error) {
// 提交所有脏状态对象
for addr := range s.stateObjectsDirty {
stateObject := s.stateObjects[addr]
if stateObject.suicided || (deleteEmptyObjects && stateObject.empty()) {
s.deleteStateObject(stateObject)
} else {
stateObject.updateRoot(s.db)
s.updateStateObject(stateObject)
}
}
// 写入trie变更
root, err := s.trie.Commit(nil)
// ... (错误处理和清理)
return root, err
}
这个过程会更新所有脏状态对象,删除自毁或空的对象,并提交 Trie 的变更。
存储树
状态树通过账户及其字段 storageRoot 引用智能合约数据,storageRoot 是账户存储树的根哈希值,即 Geth 中账户的 Root 字段:
1
2
3
4
5
6
type StateAccount struct {
Nonce uint64
Balance *big.Int
Root common.Hash // merkle root of the storage trie
CodeHash []byte
}
存储树主要通过 stateObject 结构体来管理:
1
2
3
4
5
6
7
8
9
type stateObject struct {
// ...
trie Trie // storage trie, which becomes non-nil on first access
// ...
originStorage Storage // Storage cache of original entries to dedup rewrites
pendingStorage Storage // Storage entries that need to be flushed to disk, at the end of an entire block
dirtyStorage Storage // Storage entries that have been modified in the current transaction execution
// ...
}
trie:实际的存储树,延迟加载originStorage:原始存储项的缓存pendingStorage:待刷新到磁盘的存储项dirtyStorage:当前交易执行中被修改的存储项
存储树会通过智能合约字节码中的 SLOAD 和 SSTORE 指令直接进行修改。
-
SLOAD(0x54)-
功能:从存储中加载一个字(32字节)
-
输入:从栈顶弹出一个存储位置(键)
-
输出:将对应的存储值压入栈顶
-
gas消耗:热访问100 gas,冷访问2100 gas(EIP-2929之后)
-
-
SSTORE(0x55)-
功能:将一个字(32字节)保存到存储中
-
输入:从栈顶弹出两个值,第一个是存储位置(键),第二个是要存储的值
-
输出:无
-
gas消耗:复杂,取决于操作类型(设置为非零、重置为零、修改现有值)
-
存储树中的每一个键都是存储在叶节点中的一个 Slot 的索引。该索引还要经过哈希处理。索引代表智能合约中的一个或多个全局变量,编译器在编译时确定每个变量的索引。索引 $index$ 与 Slot 的键值对在树中的存储可表示为:
\[𝑘𝑒𝑐𝑐𝑎𝑘 (𝑖𝑛𝑑𝑒𝑥) → 𝑅𝐿𝑃 (𝑠𝑙𝑜𝑡)\]以如下代码和 UML 图 14 为例来说明存储树的修改过程。假设用户已经提交了执行该智能合约的交易,并且交易字段 data 包含了被调用方法的函数签名。假设此函数已经分别以值 30、20 和 10 被调用了三次。首先在交易中定位到一个账户,然后从字段 codeHash 中执行合约,并通过 storageRoot 更新与之关联的账户存储树。由于代码清单1中的智能合约包含一个全局变量 storedData,且该变量被所执行的方法修改,因此账户存储树依次随交易的处理被修改。
1
2
3
4
5
6
7
8
9
10
contract ExampleContract {
uint storedData
event Sent ( msg );
constructor () public {}
function method ( uint x) public {
storeData = x
emit Sent ('Success ');
}
}
 图14 存储树更新
图14 存储树更新
存储树中的一个叶节点代表一个 Slot , Slot 可以包含一个或多个变量。 Slot 的宽度为32字节,其内容取决于特定变量的数据类型,Solidity 编译器文档中对此有详细说明。
有趣的是,以太坊区块链上的数据格式实际上是由 Solidity 语言定义的,Solidity 虽然是目前最流行的智能合约编程语言,但归根到底只是众多可能实现中的一种。换句话说,如果有其他编译器以不同方式存储数据,可能会生成与 Solidity 不兼容的数据存储格式。这意味着使用不同编译器或语言编写的合约可能无法正确读取或解释彼此的数据。存储在区块链上的数据本身不包含任何版本信息。这导致即使是 Solidity 自身也无法轻易改变其数据存储方式,因为这可能会破坏与现有合约的兼容性。目前,防止出现不兼容变化的主要机制是智能合约代码一旦部署就无法更新。这种不可变性确保了数据格式的稳定性,但也限制了合约的灵活性和可升级性。
在此提供当前 Solidity 生成的变量格式概述:
-
静态大小变量:多个变量会被组合在一个 Slot 中,最大可占用 32 字节。32 字节无法容纳的值会占用一个新 Slot。结构体和数组会从新 Slot 开始,并占据整个 Slot,除非其项也被打包。编译器检测到的第一个变量将被分配索引
0x0,新 Slot 依次使用下一个可用索引。 图15 静态大小变量
图15 静态大小变量图 15 中的示例展示了包含三个打包变量(
int128、int8和bool)的 Slot,以及一个无法打包的变量(int256)。合约使用继承时,其 Slot 会在存储中向后移动,以适应来自父类的状态变量,从下一个可用的 Slot 开始放置子类的变量。
-
Map:Map 首先选择一个可用的 Slot 索引 $index$,Map 中的每一个键会与该 Slot 索引进行拼接,然后计算哈希值:
\[index_{val} = keccak(index + key)\]这里的“+”表示字符串拼接。索引指向包含映射值的 Slot。注意,初始的 Slot 索引本身保持为空。图 16 中展示了从某索引开始的 Map 示例。
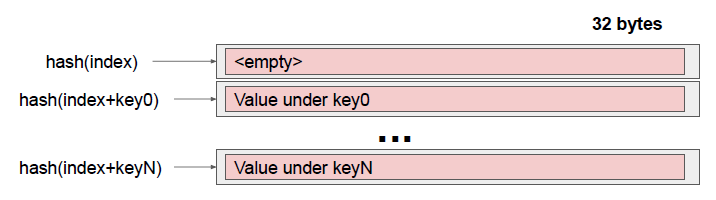 图16 Map变量
图16 Map变量 -
动态数组:为数组分配一个可用的 Slot 索引,该索引指向一个包含数组大小的 Slot(不同于 Map,数组 Slot 不为空)。该索引的哈希值指向数组的起始 Slot,所有数组元素从此索引开始顺序排列。要获取数组中的某个值,必须计算:
\[index_i = keccak(index + i)\]其中,\(index_i\) 指向数组索引 \(i\) 处的值的槽位。可以看到,数组和映射的存储方式基本相同,但数组有一个额外的优势,即如果多个变量可以放入一个槽位,则会被打包存储。图 17 展示了从某索引开始的数组示例。
 图17 动态数组
图17 动态数组 -
字节数组和字符串:当长度小于 32 字节时,会被存储在一个 Slot 中,其中一个字节用于表示长度,剩下的 31 个字节用于存储数据。对于较长的字符串或数组,其存储方式与动态数组相同:一个 Slot 存储长度,后续的 Slot 存储具体数据。图 18 展示了短字符串的示例。
 图18 字节数组和字符串
图18 字节数组和字符串
安全树
安全树 (Secure Trie) 是一种 Trie 的封装,指 Trie 中的键(路径)经过了哈希处理,并不是一种独立的数据结构。以太坊的 Geth 实现在全局状态树和账户存储树中使用了这种封装,但“安全树”这一名称已被移除。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// SecureTrie is the old name of StateTrie.
// Deprecated: use StateTrie.
type SecureTrie = StateTrie
// StateTrie wraps a trie with key hashing. In a stateTrie trie, all
// access operations hash the key using keccak256. This prevents
// calling code from creating long chains of nodes that
// increase the access time.
type StateTrie struct {
trie Trie
db database.Database
preimages preimageStore
hashKeyBuf [common.HashLength]byte
secKeyCache map[string][]byte
secKeyCacheOwner *StateTrie // Pointer to self, replace the key cache on mismatch
}
对于一个账户地址,存储在 Trie 中的键实际上不是 20 字节的地址,而是 32 字节的哈希值。这意味着当操作涉及账户地址时,必须先对该地址进行哈希处理,然后才能在 Trie 中查找或存储。同样,从账户存储树中获取的变量标识符也是经过哈希处理的,在执行 SLOAD 和 SSTORE 指令时,每个标识符都要先进行哈希处理,然后再在 Trie 中进行访问。
这样做的目的是为了防止 DOS 攻击。攻击者可能会构造特定负载(例如账户地址),使 Trie 退化为包含长路径且分支最小的结构,从而导致相应 Trie 中的查找次数急剧增加。而通过对键进行哈希处理,可以随机化其字符串表示形式,从而令分支的分布更加均匀。当然,由于每次访问都需要进行哈希计算,并且需要维护额外的缓存来映射哈希键和原始键,这也会相应地增加一些开销。
总结
本文首先对以太坊的基础数据结构和编码方案进行了详细介绍,随后对当前以太坊的区块和交易结构进行了简要说明,最后结合 Geth 讲解了执行层实现中的关键结构。同时,本文也对以太坊各轮升级带来的变化进行了梳理,参考执行层和共识层规范给出了相关的定义和代码,并结合了一些实例和插图进行说明,希望能对读者有所帮助。
参考
-
Edward Fredkin. Trie memory. Commun. ACM, 3(9):490–499, September 1960. ↩
-
Donald R. Morrison. Patricia—practical algorithm to retrieve information coded in alphanumeric. J. ACM, 15(4):514–534, October 1968. ↩
-
Ralph C. Merkle. A digital signature based on a conventional encryption function. In Carl Pomerance, editor, Advances in Cryptology — CRYPTO ’87, pages 369–378, Berlin, Heidelberg, 1988. Springer Berlin Heidelberg. ↩
-
Gavin Wood. Ethereum: A secure decentralised generalised transaction ledger shanghai version. ↩
-
Jae-Yun Kim, Jun-Mo Lee, Yeon-Jae Koo, Sang-Hyeon Park, and Soo-Mook Moon. Ethanos: Lightweight bootstrapping for ethereum. arXiv preprint arXiv:1911.05953, 2019. ↩
-
Pandian Raju, Soujanya Ponnapalli, Evan Kaminsky, Gilad Oved, Zachary Keener, Vijay Chidambaram, and Ittai Abraham. mlsm: Making authenticated storage faster in ethereum. In 10th {USENIX} Workshop on Hot Topics in Storage and File Systems (HotStorage 18), 2018. ↩